The parameter editor
On the upper right side of Porcupine’s GUI, there is a small window we call the “parameter editor”. This editor is basically a list of key-value pairs, in which the key (left column) represents the parameter name and the value (right column) represents, well, the parameter value.
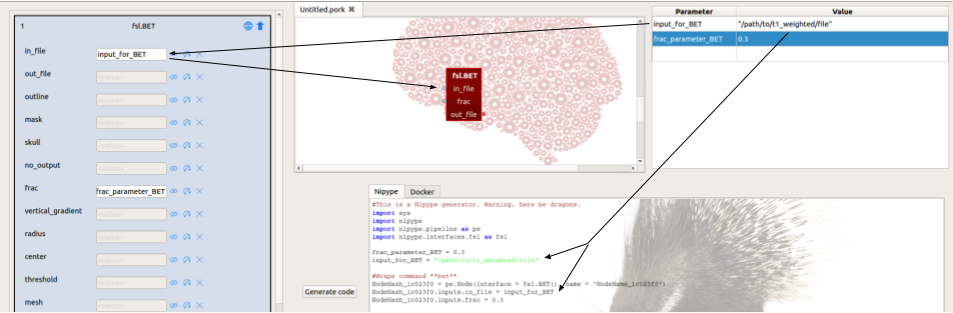
How you can use the parameter editor
In the example of the above screenshot, we for instance use the parameter editor
to hard-code two variables: input_for_BET, representing input-file (a T1-weighted scan, for example) for our
BET-node, and frac_parameter_BET, representing the fractional intensity threshold
parameter of FSL BET. Now, these two parameters can be used in the node editor
instead of their associated values. In the above example, we thus simply fill
in input_for_BET in the field of the in_file input-port of BET, instead of
typing the entire path (i.e. "path/to/t1_weighted_file"). In the code editor,
Porcupine defines these hard-coded parameters in your parameter editor at the
start of your script and subsequently assigns these variables to their assigned
input-ports.
Advantages of using the parameter editor
While you strictly don’t need the parameter editor to build whatever pipeline
you want, using it has two advantages in our opinion. First, it makes your choice
of hard-coded parameters – which are basically assumptions of your preprocessing/analysis approach –
more explicit and thus more transparent. Second, using the parameter editor may
make the values of your input-ports more legible, especially when you for example
“use/very/long/paths/pointing/to/your/data/files/and/such”. In those cases,
defining your parameters in the parameter editor keeps your node editor more organized
and “tidy”.
Alright, the parameter editor concludes the documentation on the four editors that make up Porcupine’s GUI. The next section shortly discusses how you can save and load Porcupine-pipelines and how to export your workflow editor as a PDF or SVG-image.